
增补:python3.x
1.用BS采集页面内容
2.写入CSV
3.运行的时候发现能够写入,但是写入内容如下图,全英文的OK,有中文的乱码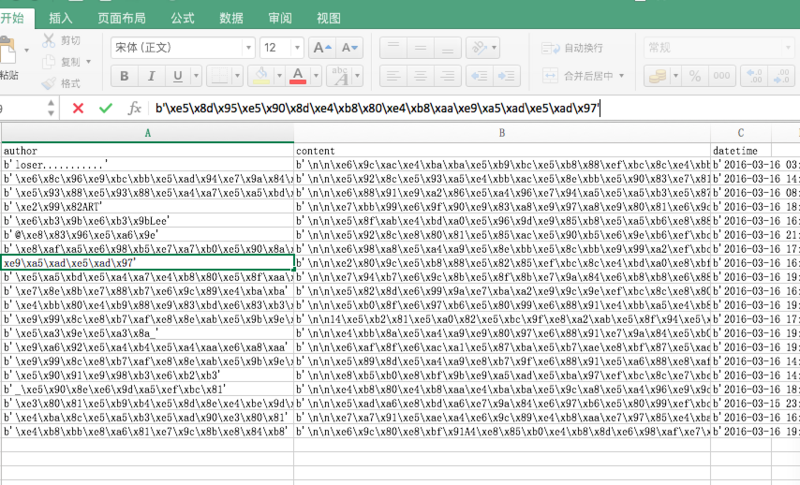
代码如下:
import io
import sys
import re
import csv
from urllib.request import Request
from urllib.request import urlopen
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
from datetime import datetime
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
page = 2
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent':user_agent}
request = Request(url,headers=headers)
response = urlopen(request)
doc = response.read()
soup = BeautifulSoup(doc)
needdivs = soup.findAll("div",{"class":"article block untagged mb15"})
csvFile = open("test.csv",'w+')
try:
writer = csv.writer(csvFile)
writer.writerow(('author','content','datetime'))
for div in needdivs:
author = div.findAll("h2")[0].get_text().encode('utf-8')
contentDiv = div.find("div",{"class":"content"})
content = contentDiv.get_text().encode('utf-8')
m = re.findall(r'<!--(.*?)-->',str(contentDiv))
strTime = str(m[0])
intTime = int(strTime)
dt = datetime.fromtimestamp(intTime)
strdt = str(dt).encode('utf-8')
writer.writerow((author,content,strdt))
print(author)
print(dt)
print(content)
finally:
csvFile.close()
我估计错误行在于 content = contentDiv.get_text().encode('utf-8')
但是我一旦去掉encode('utf-8') 那么会报下面错误
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-5:
请各位大神帮忙看看,写手写PY
====================================================
根据网上的一些,建议增加import codecs
其中 csvFile = codecs.open("test.csv",'wb+','utf-8')
里面为了比较差异
author = div.findAll("h2")[0].get_text().encode('utf-8')
另外存储的去掉了encode('utf-8')
sublime 结果为
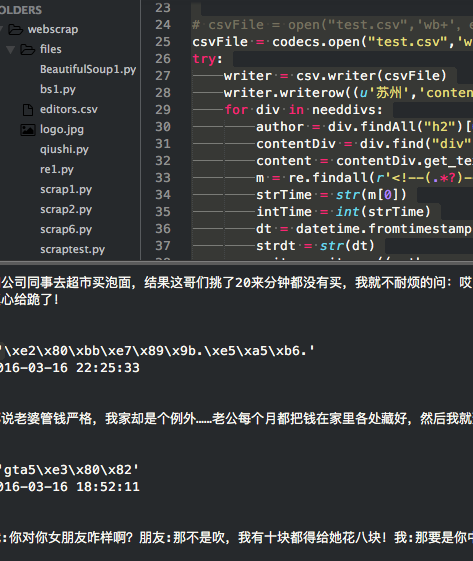
那么得到的cvs内容为

=============参考代码如下===================
import io
import sys
import re
import csv
import codecs
from urllib.request import Request
from urllib.request import urlopen
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
from datetime import datetime
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
page = 2
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent':user_agent}
request = Request(url,headers=headers)
response = urlopen(request)
doc = response.read()
soup = BeautifulSoup(doc)
needdivs = soup.findAll("div",{"class":"article block untagged mb15"})
# csvFile = open("test.csv",'wb+',encoding ='utf-8')
csvFile = codecs.open("test.csv",'wb+','utf-8')
try:
writer = csv.writer(csvFile)
writer.writerow((u'苏州','content','datetime'))
for div in needdivs:
author = div.findAll("h2")[0].get_text().encode('utf-8')
contentDiv = div.find("div",{"class":"content"})
content = contentDiv.get_text()
m = re.findall(r'<!--(.*?)-->',str(contentDiv))
strTime = str(m[0])
intTime = int(strTime)
dt = datetime.fromtimestamp(intTime)
strdt = str(dt)
writer.writerow((author,content,strdt))
print(author)
print(dt)
print(content)
finally:
csvFile.close()
如果按照这个帖子参考Python 编码转换与中文处理 那么我这里的strdt = str(dt).encode('utf-8') 是不能从str encode只能为decode但是又没有报错。见鬼了。

谢邀,不过现在在windows下,没有安装Python3.x, 等明天进linux下试一下; 另外可以试一下的是,如果是写csv文件的话,可以直接使用file, 而不是writer = csv.writer(csvFile), 这种容易出现乱码。直接写入的话,倒是很少出乱码。
csv = file('data.csv', 'wb')
csv.write(content) 这里可能会出一个问题:
字段里含有,和换行符就麻烦了,数据输出会出现混乱。这时可以使用双引号"来将每个字段内容括起来,CSV默认认为由""括起来的内容是一个栏位, 这时不管栏位内容里有除"之外字符的任何字符都可以按原来形式引用.
参考此



你导入的好几个模块我都没用过....不过能看出来是跳进了python2的encoding大坑了-_-
总之,研究了近百篇文章后我才意识到,破解encoding问题不用那么复杂.
不用''.encode().decode(),也不用sys.setdefaultencode之类
只要你在全文里除了最后输出部分,保证其余每一个字符串全都是unicode格式就行了.
比如直接手写的字符串你好,就要写成u'你好'
在比如,合并数组为字符串时, 就u''.join(arr)
其余的就unicode(s)
最后实在不行了才.decode().encode()
至于codex模块和charset, ccharset等检测字符串编码的,遇到中文一样傻眼,劝别试.
可以参考一篇我在这里看到最好的一篇解决方案,好像叫<python编码的意义>
