
因什么需求,要创建‘联合索引’?最实际好处在于什么?如果是为了更快查询到数据,有单列索引不是ok了,为什么有‘联合索引’的存在?求经验丰富老手谈谈。
最后的答案我截取了Filix Suo第二个观点里一段话为答案,创建多列索引的意义就是为了‘减少io操作’。可能使用这个会相应失去什么,这个就有待大量测试考证了。
2013/11/25 23:37更新:
今天刚入手mariadb,结果在手册里翻到了一份多列索引结构的解释(嘿嘿,真开源果然不同),贴出来供大家参考:
https://mariadb.com/kb/en/index-condition-pushdown/
创建多列索引(列1,列2,列3)后的结构类似这样(index结构,附属列,附属列)
附属列可能直接跟在叶节点上,或单独存放(这个没有看到说明)...
附带可以说明单列索引就是多列索引一种形式,只不过没有附属列罢了。。。

如下的有a,b,c 三个key的table
create table test(
a int,
b int,
c int,
);
如果我们
需要执行很多的类似于 select * from test where a=10, b>50, c>20
这类的组合查询 那么,我们可能需要创建 包含[a,b,c] 的联合索引,而单独的[a][b] [c]上的索引是不够的。
(可以把一个索引想象成 sorted list).创建了 (a,b,c)的索引相当于 按照a,b,c 排序(排序规则是
if(X.a>Y.a)
return '>';
else if(X.a<Y.a)
return '<';
else if(X.b>Y.b)
return '>';
else if (X.b<Y.b)
return '<';
else if (X.c>Y.c)
return '>'
else if (X.c<Y.c)
return '<'
esle
return '=='
)
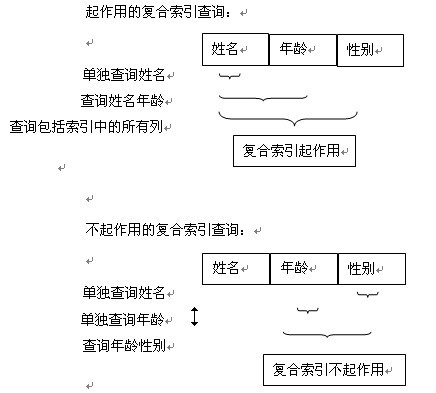
和分别 按a 排序 分别按b排序 分别按照c排序是不一样的。
其中 a b c 的顺序也很重要,有时可以是a c b,或者b c a等等。
如果创建 (a,b,c)的联合索引,查询效率如下:
优: select * from test where a=10 and b>50 差: select * from test where
a50优: select * from test order by a 差: select * from test order by b 差:
select * from test order by c优: select * from test where a=10 order by a 优: select * from test
where a=10 order by b 差: select * from test where a=10 order by c优: select * from test where a>10 order by a 差: select * from test
where a>10 order by b 差: select * from test where a>10 order by c优: select * from test where a=10 and b=10 order by a 优: select * from
test where a=10 and b=10 order by b 优: select * from test where a=10
and b=10 order by c优: select * from test where a=10 and b=10 order by a 优: select * from
test where a=10 and b>10 order by b 差: select * from test where a=10
and b>10 order by c
参考 http://blog.csdn.net/lmh12506/article/details/8879916


简单的说有两个主要原因:

举例:
创建一张数据表
CREATE TABLE `student` (
`studentId` int(11) NOT NULL,
`studentName` varchar(255) DEFAULT NULL,
`gradeId` int(11) DEFAULT NULL,
`schoolId` int(11) DEFAULT NULL,
PRIMARY KEY (`studentId`),
KEY `s_g_s` (`schoolId`,`gradeId`,`studentId`)
)
假设每个班有50名学生,一个年级有10个班,一所学校有4个年级,共有3所学校,那么总共会有6000名学生
若要查询出第2所学校3年级学生的姓名,SQL如下
SELECT studentName FROM student WHERE schoolId=2 AND gradeId=3
如果使用名为s_g_s的联合索引,那通过索引,MySQL可筛选掉大部分不满足查询条件的学生信息,在这个例子中,可筛掉5500条记录,这样MySQL只需回表查询剩余的500条记录即可得到结果。
如果只使用schoolId上的单列索引,只能筛掉4000条记录,需回表扫描过滤剩余的2000条记录才能得到结果,从数量上看差了一个数量级。性能自然不佳。
若要查询出第2所学校3年级学生的姓名并按照studentId倒排,SQL如下
SELECT studentName FROM student WHERE schoolId=2 AND gradeId=3 ORDER BY studentId DESC
这条SQL若没有多列索引,在较大数据量下性能会很差。但有了s_g_s索引,排序可以在索引上直接完成,不用MySQL取回记录后,再在内存或者磁盘上进行一次排序。性能提升很大。
若要查询出第2所学校3年级学生的studentId,SQL如下
SELECT studentId FROM student WHERE schoolId=2 AND gradeId=3
对于这条查询,s_g_s索引包含所有需要查询的字段的值,MySQL根本不需要再去读取表中的记录,直接全部在索引上完成,这是性能最高的一种索引,通常称为“覆盖索引”。
这个例子有点“简陋”,但还是可以说明一些问题。
综上,在实际项目中,
- 联合索引的使用要远多于单列索引。
- 联合索引使用正确对性能提升很有帮助。
- 怎么加索引,把哪些列加索引,加几个索引都是需要根据项目中使用到的SQL及数据表中数据的分布、数据的区分度去衡量的。
- 使用MySQL explain工具来解析SQL查询执行计划。
- 推荐看下这本书:《高性能MySQL》
