
1.地址是:http://app1.sfda.gov.cn/datas...
2.想要获取的数据是
3.调试工具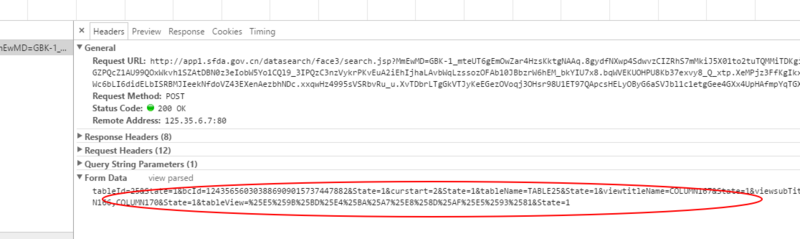
4.自己测试POST的数据返回的值是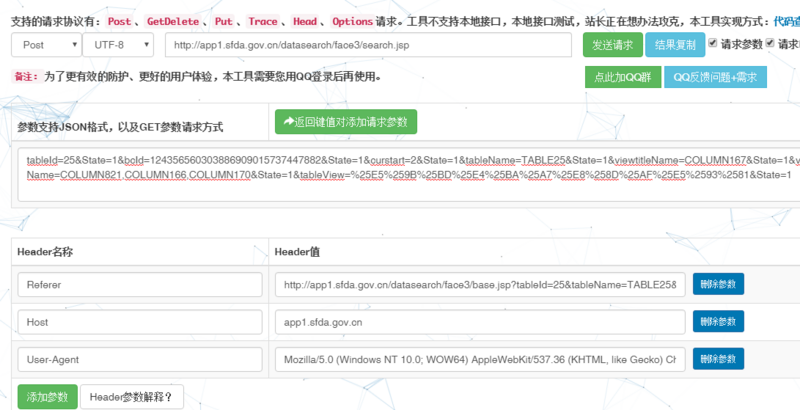

5.不知道哪里错了,求助大家了

尝试了python下使用phantomjs模拟浏览器,来抓取目标网站的首页数据
1、request.js 文件
var url="http://app1.sfda.gov.cn/datasearch/face3/base.jsp?tableId=25&tableName=TABLE25&title=%B9%FA%B2%FA%D2%A9%C6%B7&bcId=124356560303886909015737447882";
var page = require('webpage').create();
page.open(url, function(status) {
console.log(page.content);
phantom.exit();
});2、phantomjs request.js 获取的数据如下: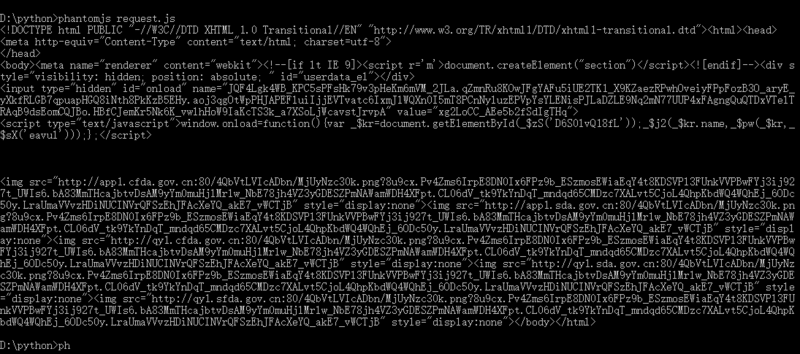
最后也还是未成功获取到网页数据 = =!


chrome ctrl + shift + j
(function () {
function devPage(jj) {
return new Promise(r => {
var curForm = document.getElementById('pageForm');
curForm.curstart.value = jj;
commitForECMA(function () {
let request = this
if (request.readyState == 4) {
if (request.status == 200) {
setTimeout(() => {
r(request.responseText)
}, 2e3)
}
}
}, 'search.jsp', curForm);
})
}
async function a() {
const el = document.createElement('html')
for (let i = 1; i <= 11035; i++) {
el.innerHTML = await devPage(i)
el.querySelectorAll('a').forEach(t => {
if (t.href.indexOf('javascript:commitForECMA(callbackC') === 0) {
console.log(t.innerHTML)
}
})
}
}
a()
})()

哪来的什么加解密。。
request.onreadystatechange = callbackC;function callbackC() {
if (request.readyState == 1) document.getElementById("content").innerHTML="<br></br><br><img src=images/loading.gif>";
if (request.readyState == 4) {
if (request.status == 200) {
oldContent[oldContent.length] = request.responseText;
document.getElementById("content").innerHTML = request.responseText;
request = null;
}
else {
document.getElementById("content").innerHTML="<br><br><br><span style=font-size:x-large;color:#215add>服务器未返回数据</span>";
}
}
}是JSESSIONID的问题啦。


