
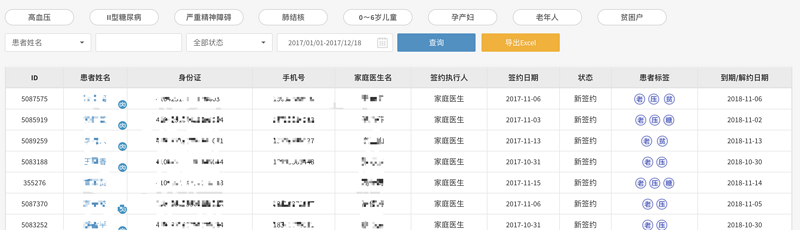
如上图示例:
历史原因:
现在做法:
技术栈:LNMP
问题:
因为是做的后台项目,整个系统几乎都是这样类似的页面;
如何优化呢?
或者采用什么技术能解决此场景下的性能瓶颈问题?
多谢各位大神!

单表千万级数据,是需要开始考虑分表的问题了!
就目前形式快速解决提供我的几个思路:
join 的地方不要用 join (我们都知道多张表使用join是做笛卡尔积的,想象下多恐怖)所以不要用join,换成单表查
千万级数据 30多秒查询
提供一下几个观点:
SSD
数据层优化:
hash 进行分表,来降低单个表的数据量;join 关联的条件,所建索引是否合适;SQL 优化:现有的 SQL 是否存在优化空间?是否能用到索引的,没有用索引?是否只查必要的字段值?SQL 在业务层优化为多条 SELECT
结构层优化:
SQL hash 结果为 key,以查询结果为 value,存入 redis



